前面我们说r模式下,文件指针会跳到开始位置,然后f.read(),就是把这个文件的内容一次性全部从硬盘读入到内存了。
这时候如果文件过大,f.read()就会有问题。如果这个文件几十个G,你还能用f.read()吗?
r模式下,f.read()是文佳指针从开头读到结尾,整个文件都给你度到内存里面来,内存一下就给占满了,这样的话32G内存都不够你用的。
当然文件小的话这样做没问题,文件大的话就不行了。
现在我把读到的内容复制给res1,然后再打印一下res1.
with open(r'G:\PythonProject\学习\学习文件\date\a.txt', mode='rt', encoding='utf-8') as f:
...
res1=f.read()
print(res1)接着我再用f.read()来读一次。
with open(r'G:\PythonProject\学习\学习文件\date\a.txt', mode='rt', encoding='utf-8') as f:
...
res1=f.read()
print(res1)
res2=f.read()
print(res2)为了区分一下两次读写的内容,我在前面打印一下分隔符,center功能,80个字符用横杠填充。
然后第二次读我也这么打印一下。
with open(r'G:\PythonProject\学习\学习文件\date\a.txt', mode='rt', encoding='utf-8') as f:
...
print('第一次读'.center(80,'-'))
res1 = f.read()
print(res1)
print('第二次读'.center(80,'-'))
res2 = f.read()
print(res2)现在我要运行这个程序的话会发生什么?我们先来分析一下,f.read()前面是说过,读完后文件指针在末尾了。
第二次读,的时候文件指针就已经在末尾了 ,就什么也读不到。
我们来运行看看是不是分析的结果。

结果和我们分析的一样。
所以只要我们呢个够控制这个文件指针的移动是不是就可以随性所欲想读哪段内容就可以读哪段内容了。
也可以避免r模式下的f.read()会一次性把整个文件内容读入内存,造成内存被占满的问题。
控制文件指针是我们后面要讲的,现在还有一个点你要注意。
你注意看,第一次读完之后,有个换行。
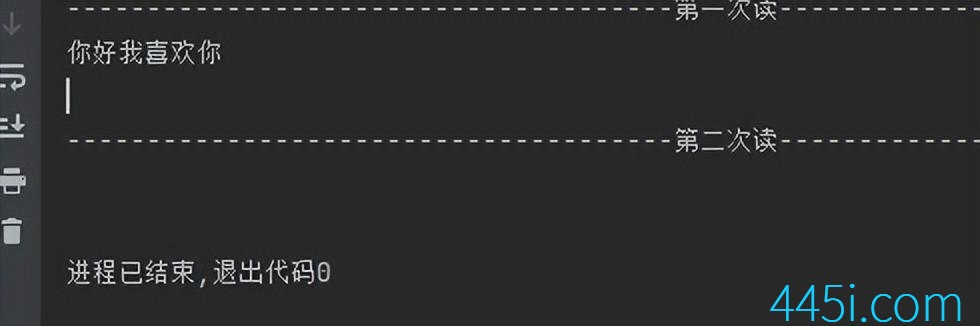
为什么呢?我们的文件内容不就是‘你好我喜欢你’这句话吗?来看这个文件内容。

这个文件里面本来就有个换行符,也就是说\n,虽然这个\n我们看不见,但是我们读文件的时候这个\n也是会读进去的。
未经允许不得转载:445IT之家 » Python 文件指针

